


DeepSeek-GRM: What It Is and Why You Should Care
A new generalist reward model from DeepSeek AI

At the heart of recent AI advancements lies reward modeling—a mechanism for providing accurate reward signals to guide model optimization. A few days ago, a new paper from DeepSeek AI introduced a novel approach that significantly advances the field by making reward models more effective and scalable across diverse domains.
While we've seen impressive progress in reward modeling for specific domains with clear verification criteria (like mathematics or coding), generating high-quality rewards for general domains remains challenging.
This might not be another “DeepSeek moment”, but it’s a pretty significant contribution that, for some reason, hasn’t really been picked up yet by the wider AI community—which is why I decided to write about it.
In this article, we'll explore the key innovations of their research, explain the technical details of the proposed method, Self-Principled Critique Tuning (SPCT) and inference-time scaling for reward models.
Before we dive into it though, let’s start with an (optional) executive summary that will give you a better idea of what DeepSeek-GRM is about.
Executive Summary
DeepSeek AI’s latest release focuses on improving reward modeling (RM) for large language models (LLMs) through "inference-time scaling." In simple terms, it's about how to make reward models get better results by using more compute at inference time, rather than just making bigger models during training.
Key themes and contributions:
Introducing Self-Principled Critique Tuning (SPCT), a method for generalist reward modeling
Developing a reward modeling approach using pointwise generative reward modeling (GRM)
Showing how to effectively scale inference computation for better reward quality
Creating DeepSeek-GRM models that outperform existing approaches
Introducing a meta RM to guide voting process for better scaling performance
Main challenges addressed:
Flexibility for different input types in reward modeling
Accurate reward generation in various domains
Scaling reward quality with increased inference compute
Learning scalable behaviors for better performance-compute scaling
Key methods:
Pointwise generative reward modeling (GRM)
Self-Principled Critique Tuning (SPCT) with:
Rejective fine-tuning
Rule-based online reinforcement learning
Inference-time scaling through:
Parallel sampling
Meta RM-guided voting
Key results:
DeepSeek-GRM outperforms baseline methods on various reward modeling benchmarks
Inference-time scaling provides significant performance improvements
Voting with meta RM guidance further boosts performance
Inference-time scaling can outperform training-time scaling (using larger models)
The Challenge: Building Better Generalist Reward Models
Reward modeling serves as the backbone of Reinforcement Learning from Human Feedback (RLHF), providing the signals that guide LLMs toward generating more helpful, harmless, and honest responses. While high-quality rewards exist for specific domains with clear verification criteria (like mathematics or coding), generating accurate rewards for general domains remains challenging. The researchers identify four key requirements for effective generalist reward models:
Flexibility to handle different input types (single responses, paired comparisons, or multiple candidates)
Accuracy in generating rewards across diverse domains
Inference-time scalability to improve reward quality with more compute
Learning scalable behaviors that enhance performance as compute increases
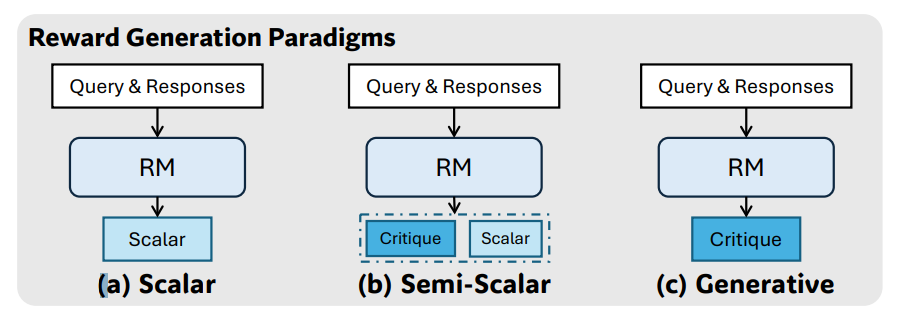
Existing approaches to reward modeling fall into several categories, each with limitations:
Scalar reward models: Output numerical scores but lack detailed reasoning
Semi-scalar reward models: Generate both scores and critiques but struggle with scaling
Generative reward models: Provide detailed textual critiques but need methods to scale effectively
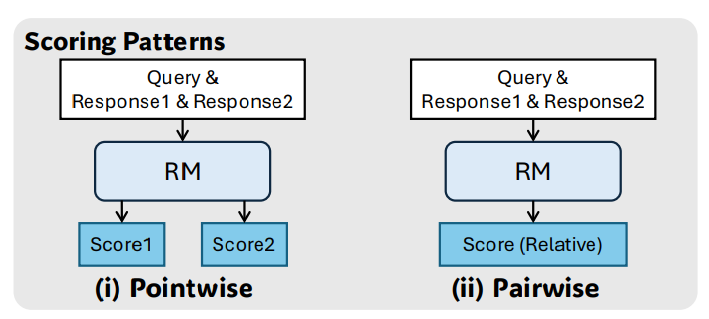
Additionally, reward models use either pointwise scoring (rating each response individually) or pairwise scoring (selecting the better of two responses). They found that pointwise generative reward models (GRMs) offer the best combination of flexibility and scalability potential.
The Power of Principles in Reward Generation
A key insight from the paper is that quality principles significantly improve reward generation. In preliminary experiments, the researchers discovered that properly selected principles boosted reward quality on benchmarks like Chat Hard and IFEval. Rather than using static principles, they explored allowing the model to dynamically generate principles tailored to each query and response pair. For example, when evaluating responses to a coding question, the model might generate principles like:
Code Correctness (Weight: 40%)
Code Efficiency (Weight: 25%)
Documentation Quality (Weight: 20%)
Error Handling (Weight: 15%)
These weighted principles create a structured framework for generating comprehensive critiques and more accurate rewards.
Self-Principled Critique Tuning: Teaching Models to Generate Better Principles and Critiques
The core contribution of this paper is Self-Principled Critique Tuning (SPCT), a method that enables generative reward models to learn generating adaptive, high-quality principles that guide critique generation.
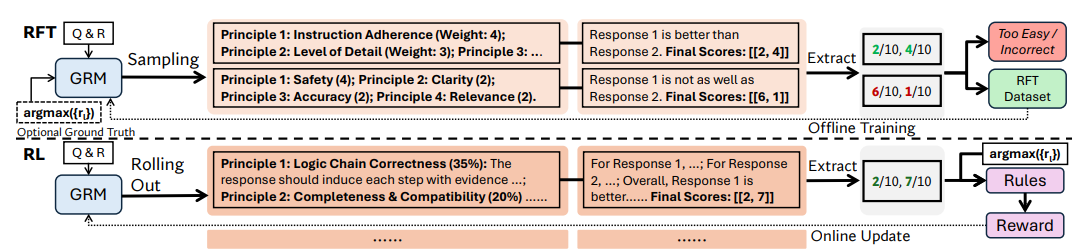
If this image is as confusing to you as it was to me: don’t worry, we’ll go through it together—step by step.
See the “RFT” and “RL” on the left? RFT stands for “Rejective Fine-Tuning” and RL for “Reinforcement Lerning”, or more specifically in this case, “Rule-Based Online Reinforcement Learning”. Those are the two phases of SPCT training.
Phase 1: Rejective Fine-Tuning (RFT)
The first phase prepares the model to generate well-formatted principles and critiques for various input types:
Data construction: Sampling trajectories (principles and critiques) from pretrained GRMs for queries and responses
Rejection strategy: Discarding trajectories where predicted rewards don't align with ground truth, and removing "too easy" queries where all sampled trajectories are correct
Optional hinting: For challenging cases, providing hints about the correct answer, though this sometimes leads to "shortcuts" in reasoning
This phase creates a unified format for handling different numbers of responses, unlike previous approaches that used different formats for different scenarios.
Phase 2: Rule-Based Online Reinforcement Learning (RL)
The second phase refines the model's ability through online reinforcement learning:
During rollout, the model generates principles and critiques for input queries and responses
The predicted rewards are extracted and compared to ground truth
The model receives binary rewards: +1 for correctly identifying the best response, -1 otherwise
The reinforcement learning objective includes a KL penalty to maintain format quality
This approach encourages the model to develop principles that enable accurate discrimination between responses while avoiding severe biases.
Scaling at Inference Time: More Compute, Better Results
Once trained with SPCT, DeepSeek-GRM models demonstrate remarkable inference-time scalability through two key methods:
1. Voting with Generated Rewards
The basic approach involves:
Running the model multiple times with different random seeds (parallel sampling)
Having each sample generate its own set of principles and critiques
Extracting numerical scores from each run
Summing the scores to determine the final ranking
Since each sample generates different principles, the model evaluates responses from multiple perspectives, leading to more robust judgments. This process effectively expands the reward space, allowing for finer distinctions between responses.
2. Meta Reward Modeling for Better Voting
To further enhance performance, the researchers introduced a meta reward model that:
Evaluates the quality of principles and critiques generated by the main reward model
Assigns scores to indicate which samples are more reliable
Guides the voting process by filtering out low-quality samples
This meta RM is trained to identify the correctness of principles and critiques, using both positive and negative examples to improve performance.
Impressive Results Across Diverse Benchmarks
The researchers evaluated DeepSeek-GRM models on multiple reward modeling benchmarks including Reward Bench, PPE (both Preference and Correctness), RMB, and ReaLMistake. The results demonstrate several significant findings:
DeepSeek-GRM Outperforms Baseline Methods
Even without inference-time scaling, DeepSeek-GRM-27B (based on Gemma-2-27B) achieved superior overall performance compared to baseline methods like LLM-as-a-Judge and various scalar and semi-scalar reward models. Unlike scalar and semi-scalar reward models that showed strong biases (performing well on some benchmarks but poorly on others), DeepSeek-GRM demonstrated more consistent performance across diverse domains.
Inference-Time Scaling Significantly Improves Performance
The most striking results come from inference-time scaling:
With 8 samples, DeepSeek-GRM-27B showed a performance increase of 2.7 percentage points
With meta RM guidance and 32 samples, it achieved a remarkable 4.9 percentage point improvement
This scaled performance reached levels competitive with or exceeding much larger models like GPT-4o and Nemotron-4-340B-Reward
What's particularly noteworthy is that these improvements far exceeded those of baseline methods under similar scaling conditions.
Inference-Time Scaling vs. Training-Time Scaling
Perhaps most importantly, the researchers showed that inference-time scaling can be more effective than simply using larger models:
DeepSeek-GRM-27B with meta RM-guided voting (32 samples) achieved performance comparable to a 671B parameter model using greedy decoding
This suggests that allocating more compute to inference might be more cost-effective than training larger models
This finding challenges the conventional wisdom that "bigger is better" and offers a more nuanced view of compute allocation.
Why SPCT Works: Technical Analysis
The effectiveness of SPCT stems from several key design choices:
Unified pointwise GRM format enables flexible handling of different input types within the same model
Self-generated principles create a tailored framework for critique that focuses on relevant criteria
Rule-based reinforcement learning teaches the model to generate principles that enable effective discrimination
Parallel sampling with diverse principles evaluates responses from multiple perspectives
Quality control via meta RM ensures only reliable samples contribute to the final decision
The principles serve as a form of chain-of-thought reasoning, helping the model organize its evaluation process and producing more consistent rewards.
Limitations and Future Directions
Despite its impressive performance, the approach has several limitations:
Efficiency challenges: Generative reward models require more computation than scalar models for each inference
Domain-specific performance: DeepSeek-GRM still lags behind scalar models on some verifiable tasks
Long-horizon reasoning: The researchers found that DeepSeek-R1, which uses extensive chain-of-thought reasoning, underperformed relative to its computational cost except on reasoning-intensive tasks
These limitations point to several promising future directions:
Tool integration: Incorporating tools like code interpreters could enhance verification capabilities
Efficiency improvements: Generating principles ahead of time could improve computational efficiency
LLM evaluation applications: Using generated principles as interpretable criteria for identifying LLM weaknesses
Co-scaling with policy models: Combining scalable rewards with scalable policies for even greater performance
Conclusion: A Significant Advance in Reward Modeling
Self-Principled Critique Tuning represents a significant advance in reward modeling for LLMs. By enabling generative reward models to dynamically produce principles tailored to specific queries and responses, SPCT creates models that are both flexible across diverse inputs and effectively scalable with increased inference compute.
The impressive performance of DeepSeek-GRM models, particularly with inference-time scaling, suggests that this approach could become an important component of future LLM training pipelines. The finding that inference-time scaling can outperform training-time scaling (using larger models) is particularly noteworthy, offering a potentially more efficient path to improved reward modeling.
In a field where much attention focuses on scaling model size, this research offers a refreshing perspective: sometimes, using compute more intelligently at inference time can be more effective than simply building bigger models.
State of AI Agents: What OpenAI & Google Are Planning

Welcome to the first article of this new series! We’re one week into April there’s already a lot to talk about. From major product launches to strategic shifts to research insights: things aren’t slowing down, it seems.
My first thought is how does this change/affect the prompt I would use.