


🛒 Getting RAG Right: All in One Go
And how attention maps might help us understand hallucinations

In this issue:
One-Stop-RAG-Shop
Hallucinations through the lens of attention maps
Plug-n-Play Prompt Automation

1. RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs
Watching: RankRAG (paper)
What problem does it solve? Retrieval-augmented generation (RAG) is a powerful technique that allows language models to access external knowledge during inference. However, the effectiveness of RAG heavily relies on the quality of the retrieved contexts. Existing approaches often use a separate retriever model to rank and select the top-k contexts, which can be suboptimal and computationally expensive. RankRAG addresses this issue by proposing a unified framework that instruction-tunes a single language model for both context ranking and answer generation.
How does it solve the problem? RankRAG introduces a novel instruction fine-tuning approach that enables a single language model to excel at both context ranking and answer generation. By incorporating a small fraction of ranking data into the training blend, the instruction-tuned model learns to effectively rank and select the most relevant contexts for a given query. Surprisingly, this approach outperforms even the same language model that is exclusively fine-tuned on a large amount of ranking data. The unified model architecture of RankRAG streamlines the RAG pipeline and eliminates the need for a separate retriever model.
What's next? The performance of RankRAG on various knowledge-intensive benchmarks, surpassing strong baselines like GPT-4 and ChatQA-1.5, highlights the potential of this unified instruction fine-tuning approach. Moreover, RankRAG's ability to generalize to new domains, such as the biomedical domain, without domain-specific instruction fine-tuning, opens up possibilities for its application in specialized fields. Future research could explore the scalability of RankRAG to even larger language models and investigate its performance on a wider range of domain-specific tasks.
2. Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps
Watching: Attention Maps (paper)
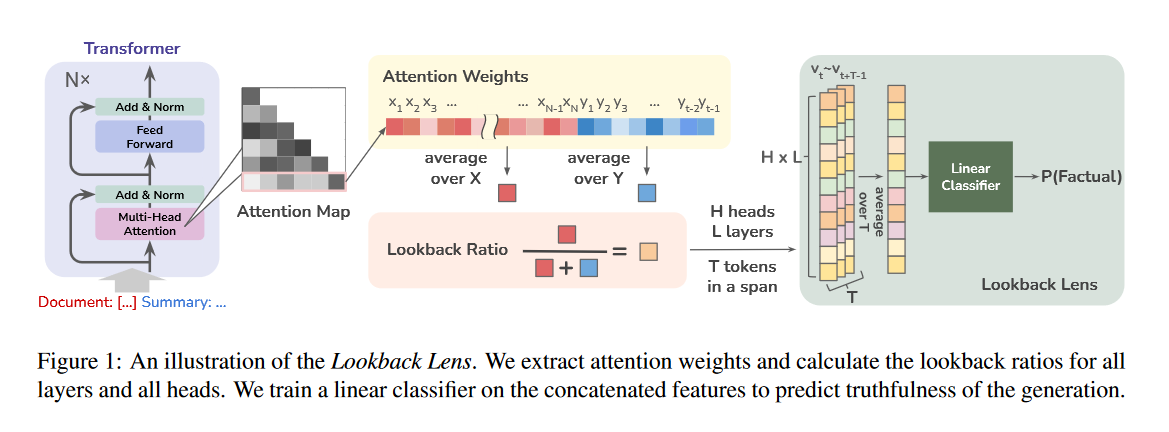
What problem does it solve? Large Language Models (LLMs) have a tendency to generate outputs that are not always fully grounded in the provided context. This phenomenon, known as hallucination, can lead to inaccurate or misleading responses when the model is asked to summarize articles or answer questions based on a given passage. Detecting and mitigating such contextual hallucinations is crucial for improving the reliability and trustworthiness of LLMs in real-world applications.
How does it solve the problem? The proposed approach, called Lookback Lens, leverages the attention mechanism of LLMs to detect contextual hallucinations. The key idea is to examine the ratio of attention weights that the model assigns to the provided context versus its own generated tokens. By training a simple linear classifier on these lookback ratio features, the authors demonstrate that it is possible to effectively detect hallucinations without the need for more complex models that rely on the entire hidden states of the LLM or text-based entailment. Remarkably, the detector is found to be transferable across tasks and even different-sized models, allowing for efficient deployment without retraining.
What's next? By applying the trained detector during the decoding process, the authors show that it is possible to reduce the amount of hallucination in tasks such as summarization. This classifier-guided decoding approach could be further refined and integrated into various LLM-based applications to enhance their accuracy and reliability. Additionally, exploring the combination of Lookback Lens with other techniques, such as reinforcement learning or adversarial training, may lead to even more effective strategies for addressing the challenge of contextual hallucinations in LLMs.
3. PAS: Data-Efficient Plug-and-Play Prompt Augmentation System
Watching: PAS (paper)
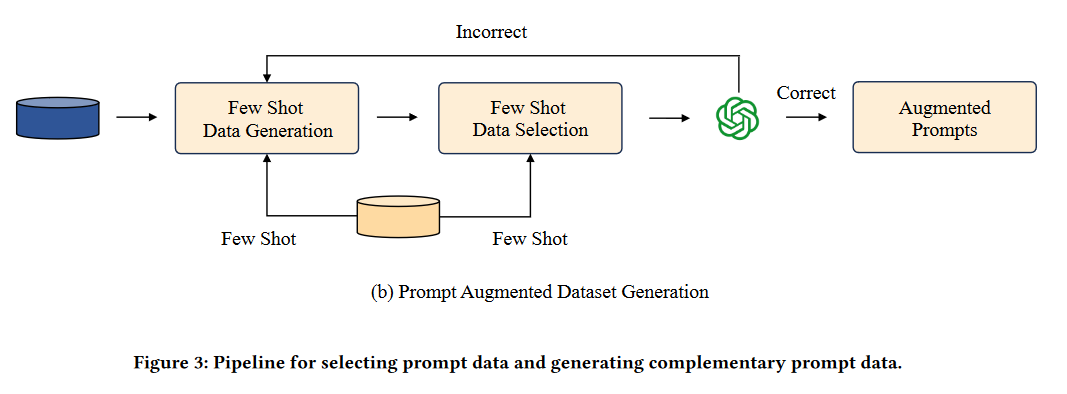
What problem does it solve? Prompt engineering has become a crucial skill for effectively utilizing Large Language Models (LLMs). However, crafting high-quality prompts can be challenging and time-consuming, even for experienced users. Existing automatic prompt engineering (APE) models aim to alleviate this issue, but they often fall short in terms of usability and performance. PAS addresses these limitations by providing a plug-and-play APE system that is easy to use and delivers state-of-the-art results.
How does it solve the problem? PAS leverages the power of LLMs to generate high-quality prompt complementary datasets automatically. By training on these datasets, PAS achieves exceptional performance in prompt engineering tasks. The system is highly efficient, requiring only 9000 data points to reach state-of-the-art performance, which is a significant improvement over previous APE models. Additionally, PAS can autonomously generate prompt augmentation data without the need for human intervention, further streamlining the prompt engineering process.
What's next? The flexibility of PAS makes it compatible with all existing LLMs and applicable to a wide range of tasks, positioning it as a valuable tool for enhancing the usability and effectiveness of LLMs. As the demand for plug-and-play AI systems continues to grow, PAS has the potential to become a go-to solution for users seeking to improve their prompt engineering capabilities. Future research could focus on further refining the system's performance, expanding its applicability to even more diverse tasks, and exploring ways to integrate PAS seamlessly into existing LLM workflows.
Papers of the Week:
RATT: A Thought Structure for Coherent and Correct LLM Reasoning
Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting
Towards Building Specialized Generalist AI with System 1 and System 2 Fusion
Nice review of various different activities and practices!!
RankRAG Instruction Adjusts LLM to Simultaneously Capture Relevance Between Questions and Context, Utilizing Retrieved Context to Generate Answers.
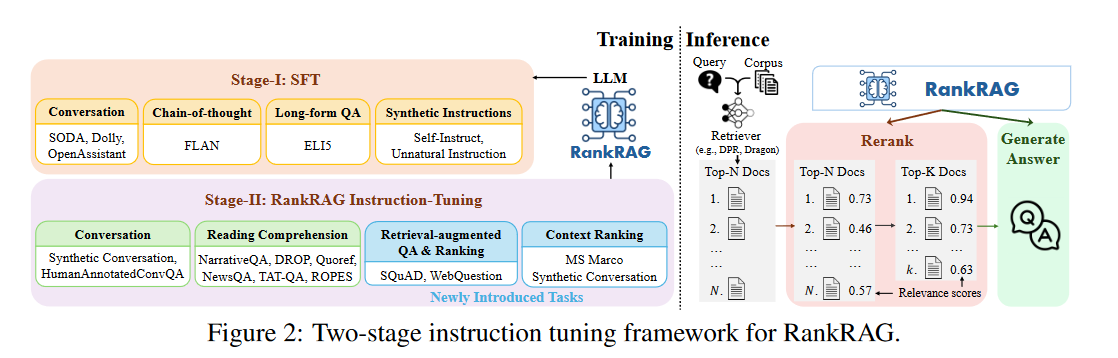
Phase 1: Supervised Fine-Tuning (SFT)
The language model is fine-tuned using a high-quality instruction-following dataset, which includes conversation datasets, chain-of-thought datasets, long-form QA datasets, and LLM-generated instruction datasets (Synthetic Instructions). In a multi-turn conversation format, the conversation history between the user and the assistant is used as context, and loss is calculated at the assistant's final response. A total of 128,000 SFT samples were used.
Phase 2: Unified Instruction Fine-Tuning for Ranking and Generation
The first phase of SFT provides the LLM with basic instruction-following capabilities. However, their performance on RAG tasks is often suboptimal, as the LLM is not optimized for extracting answers from the retrieved context given a specific question. RankRAG adjusts the LLM for retrieval-augmented generation and context ranking instructions, with context ranking capabilities being particularly crucial for obtaining more relevant top-K contexts in cases where the retriever is not perfect.