


🦾 Google Releases Transformer 2.0
And how to train your own version of o1-preview on a budget

In this issue:
From Transformers to Titans
Smaller, weaker, yet better
O1-preview-level results for <$450

Interested in real-world applications of vision AI agents?
In this upcoming webinar from NVIDIA, you'll learn how leading companies are adopting Generative AI ,including real-world applications and their technical implementation.
If you want to learn about their best practices, then sign up now for free:
1. Titans: Learning to Memorize at Test Time
Watching: Titans (paper)
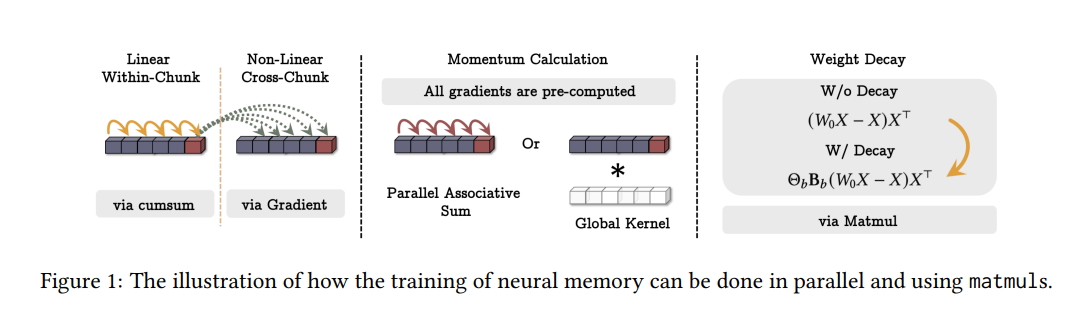
What problem does it solve? The authors address the limitations of current attention mechanisms in handling long-term dependencies, specifically the trade-off between recurrent models (which compress data into fixed-size memory) and attention mechanisms (which have quadratic computational costs and limited context windows).
How does it solve the problem? They introduce a new neural long-term memory module that works alongside attention mechanisms, creating a hybrid approach called Titans. This module learns to memorize historical context while allowing attention to focus on current context, effectively combining the benefits of both short-term (attention) and long-term (neural memory) information processing.
What are the key findings? Titans outperformed both traditional Transformers and modern linear recurrent models across various tasks including language modeling, common-sense reasoning, genomics, and time series analysis. Most notably, they can effectively handle context windows larger than 2M tokens while maintaining higher accuracy in needle-in-haystack tasks.
Why is this important? Being able to fully utilize the strengths of both recurrent networks and Transformers at the same time could enable more efficient and accurate processing of lengthy documents, complex sequences, and tasks requiring long-term memory, while maintaining computational efficiency. This is particularly relevant as the demand for models capable of handling increasingly longer contexts continues to grow.
2. Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling
Watching: Training LLM Reasoners (paper)
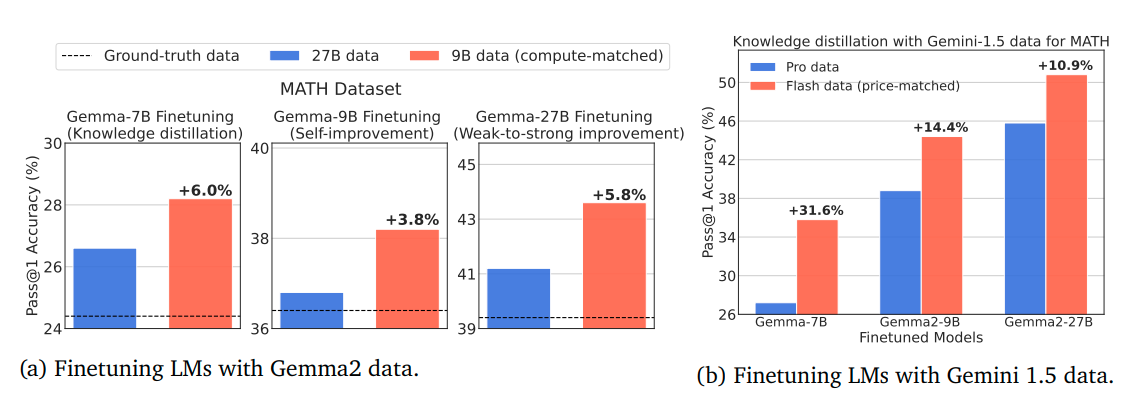
What problem does it solve? The article challenges the common practice of using strong but computationally expensive language models (LMs) to generate synthetic training data for improving reasoning performance, questioning whether this approach is truly compute-optimal.
How does it solve the problem? The authors conducted a comparative analysis between stronger but expensive (SE) and weaker but cheaper (WC) models for generating synthetic data, evaluating them across three metrics: coverage, diversity, and false positive rate. They then tested different finetuning settings including knowledge distillation, self-improvement, and a novel weak-to-strong improvement setup.
What are the key findings? They found that WC models' generated data had higher coverage and diversity, though with higher false positive rates. Surprisingly, models finetuned on WC-generated data consistently outperformed those trained on SE-generated data across multiple benchmarks, challenging the conventional wisdom of using stronger models for synthetic data generation.
Why is this important? As the performance gap between small and large LMs continues to narrow, this could provides a framework for compute-optimal training that could make the development of advanced AI systems more accessible and efficient. This would have major implications for organizations with limited computational resources who want to develop capable language models.
3. Sky-T1: Train your own O1 preview model within $450
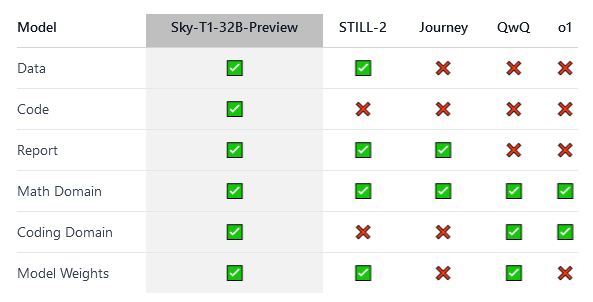
What problem does it solve? The authors tackle the challenge of replicating high-level reasoning capabilities in language models that are typically found in closed-source models like o1 and Gemini 2.0, while making it accessible and affordable for the academic and open-source communities.
How does it solve the problem? They developed Sky-T1-32B-Preview, a fully open-source reasoning model, and trained it for less than $450. They made all components publicly available, including infrastructure, training data (17K samples), technical details, and model weights, enabling complete reproducibility.
What are the key findings? Sky-T1-32B-Preview performs on par with o1-preview on popular reasoning and coding benchmarks, demonstrating that high-level reasoning capabilities can be achieved with relatively modest resources and an open-source approach.
Why is this important? Work like this could democratize access to advanced AI capabilities by proving that competitive reasoning models can be developed at a fraction of the cost typically associated with such systems. This opens up opportunities for broader participation in AI research and development, particularly for academic institutions and independent researchers who may have limited resources.
Papers of the Week:
SWE-Fixer: Training Open-Source LLMs for Effective and Efficient GitHub Issue Resolution
SUGAR: Leveraging Contextual Confidence for Smarter Retrieval
Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
Lifelong Learning of Large Language Model based Agents: A Roadmap
The Lessons of Developing Process Reward Models in Mathematical Reasoning
O1 Replication Journey -- Part 3: Inference-time Scaling for Medical Reasoning
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models